YOLOv3 in PyTorch
本文最后更新于:Friday, December 25th 2020, 12:17 pm
Intro
YOLO, aka “You Only Look Once”—> 名字是不是很酷YOLO是
object detection领域非常出名的算法,它以速度快同时兼顾性能著称。
1 Net Architecture
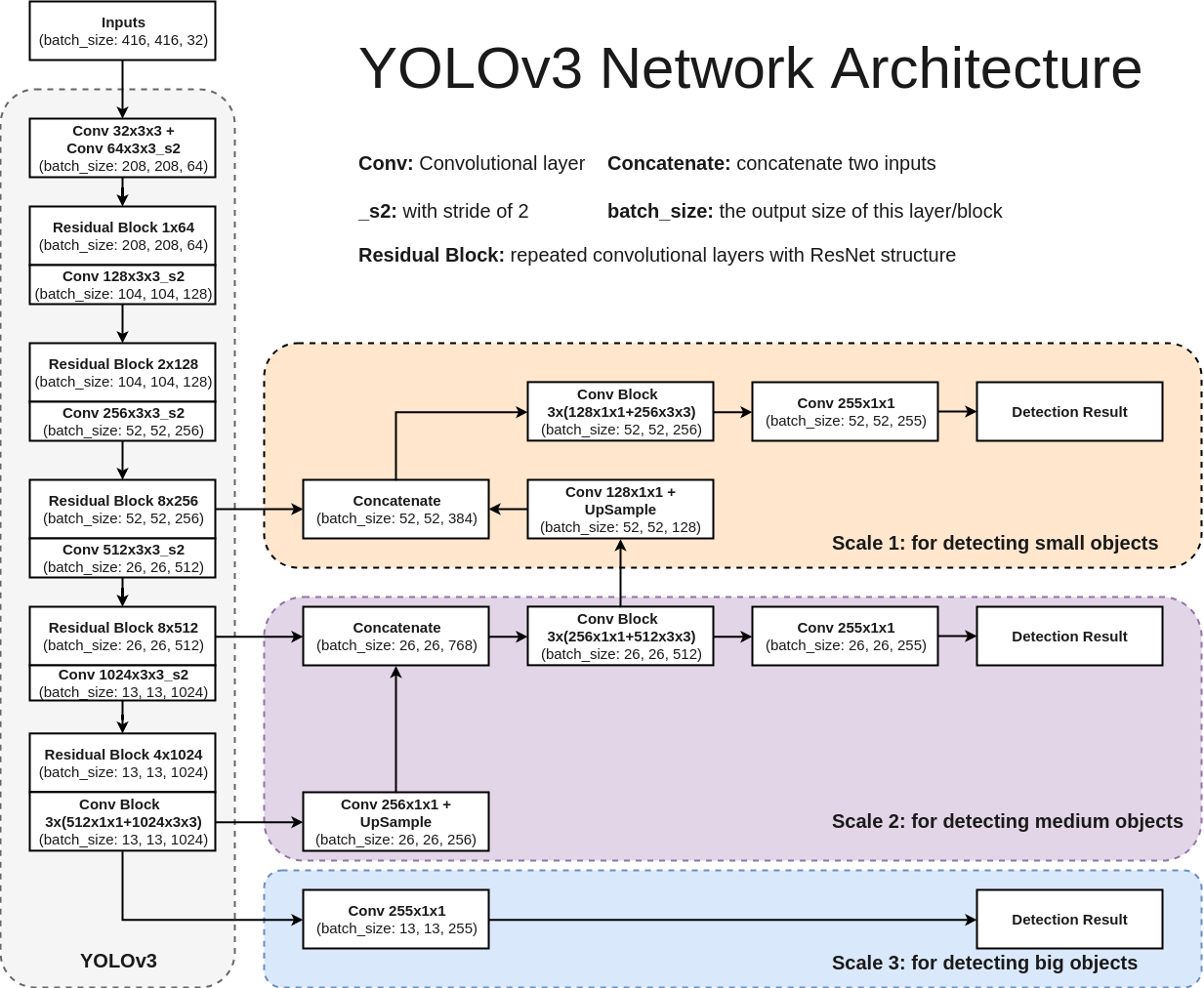
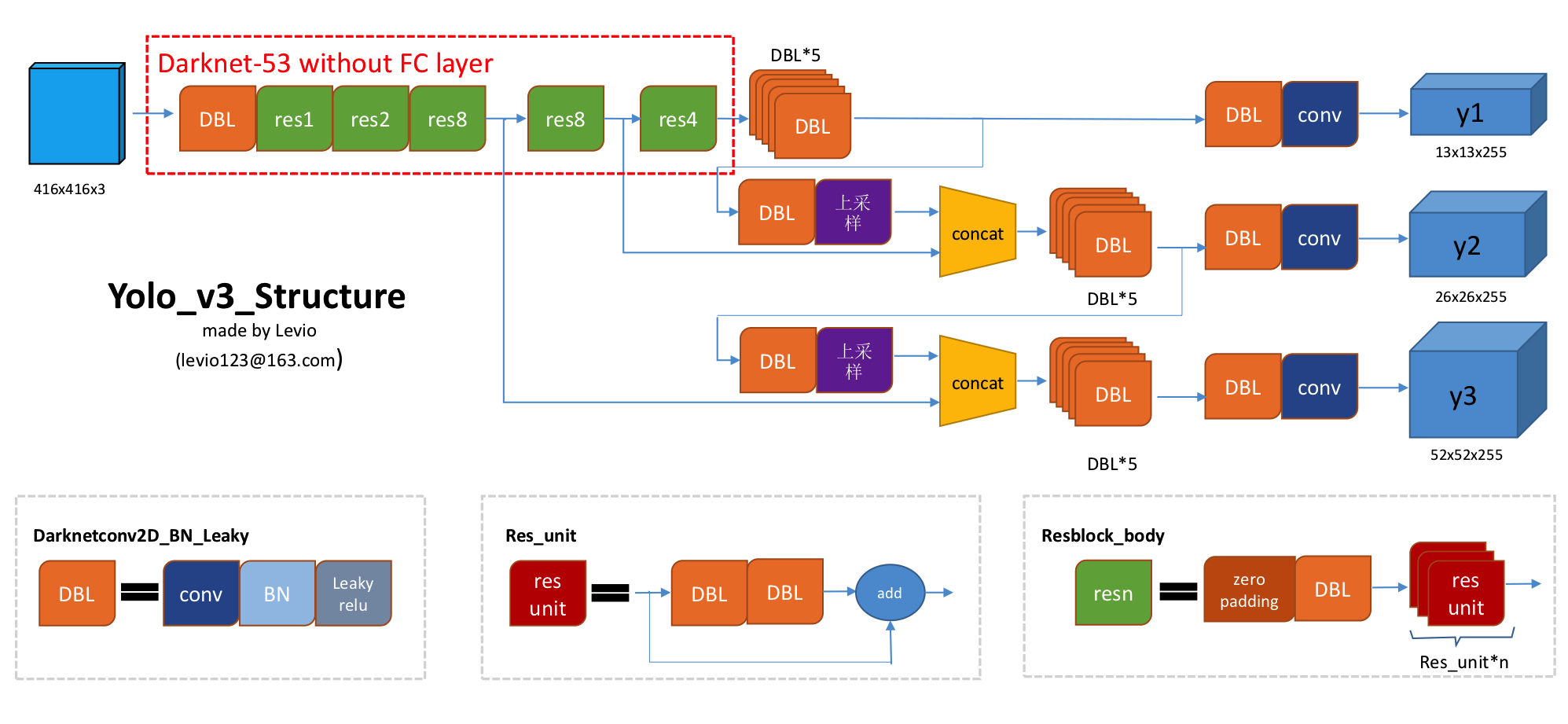
concatenate层在Yolo里面叫做route层res_unit层在Yolo里面叫做shortcut层detection层在Yolo里面叫做yolo层
2 Details
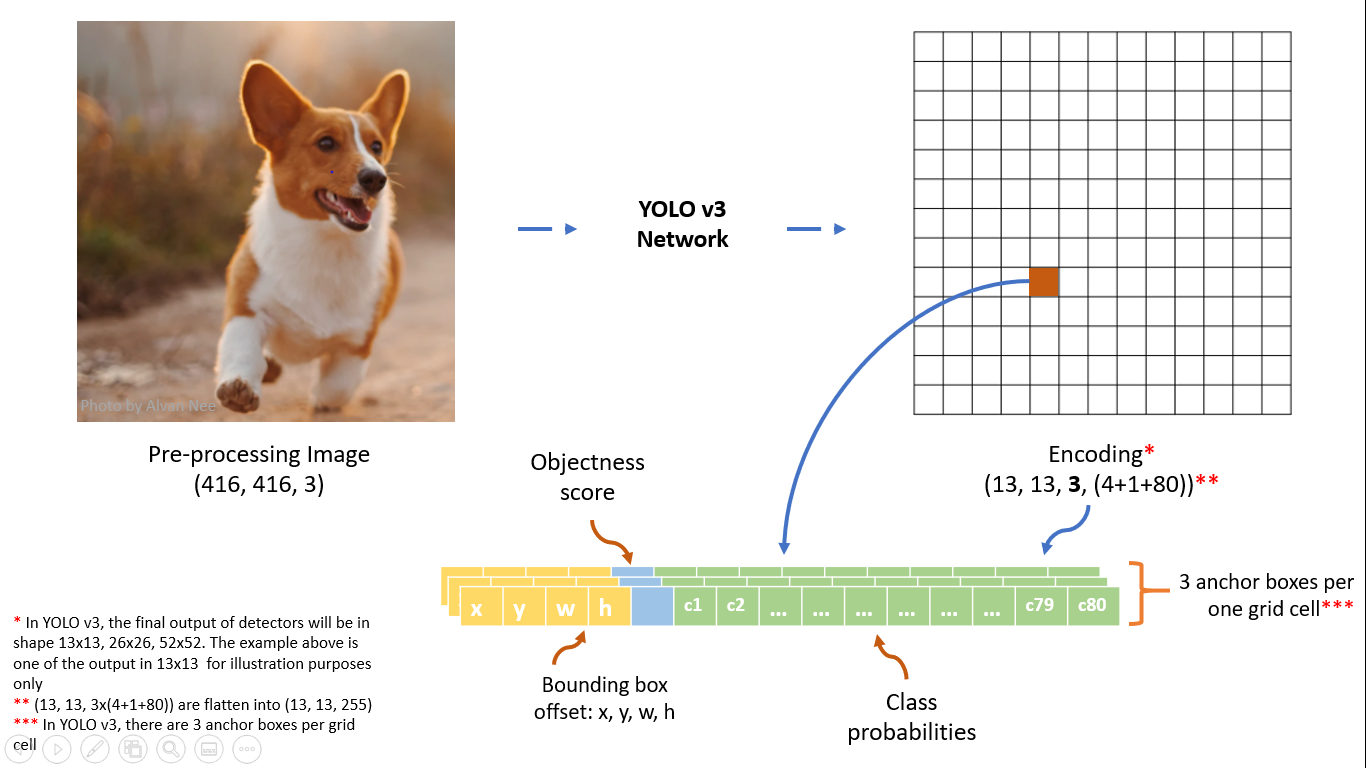
输入层:
416*416*3将输入划分为$S * S$ grid, 每个格子有三个预先设定好长($p_w$)和宽($p_h$)的anchor box;如果物体的中心落在哪个grid, 那个grid就负责探测该物体。
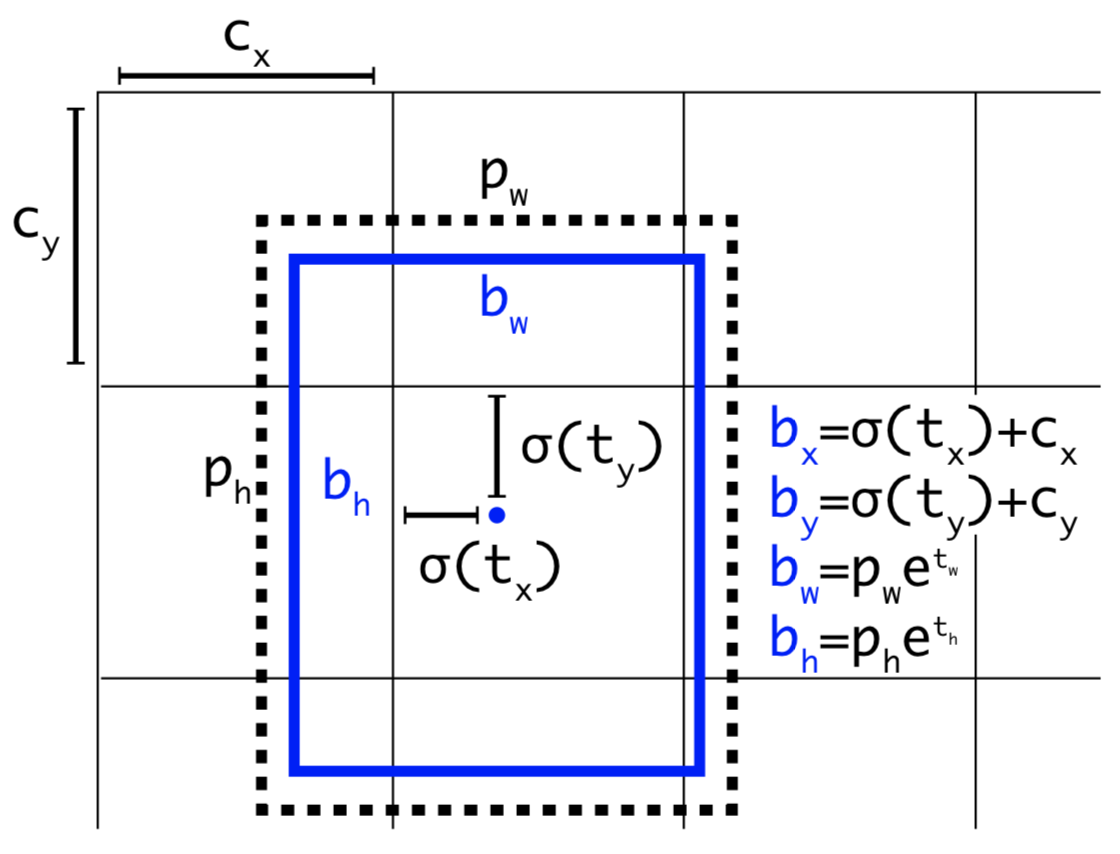
每个anchor box有85个数据[$t_x, t_y, t_w, t_h, objectscore, c1, c2…]$,分别代表:
- 预测框中心点坐标:网络实际输出的是$t_x 和 t_y$, 为了让该cell预测的物体中心一定落在该cell上,加了个sigmoid函数。
- 预测框长和宽: 防止梯度下降不稳定,所以进行了对数空间变换,网络给出$t_x, t_h$, 真实的长和宽由👆公式计算。
- 是否有物体的概率: 如果没有物体,后续类别的置信分数将没有作用
- 一共预测80个类别,每个类别的置信分数。

有三种scale的输出层,分别为:
13 * 13 * 85;26 * 26 * 85;52 * 52 * 85;每个cell有三个anchor box;所以每个输入一共有$(13\times13+26\times26+52\times52)\times3=10647$个预测框
这么多输出框肯定绝大部分是重复预测或者不正确的预测,需要剔除不好的框
- 设置
object score阈值,比如低于0.6的去除 - 设置
IOU阈值,进行Non-maximum Suppression
- 设置
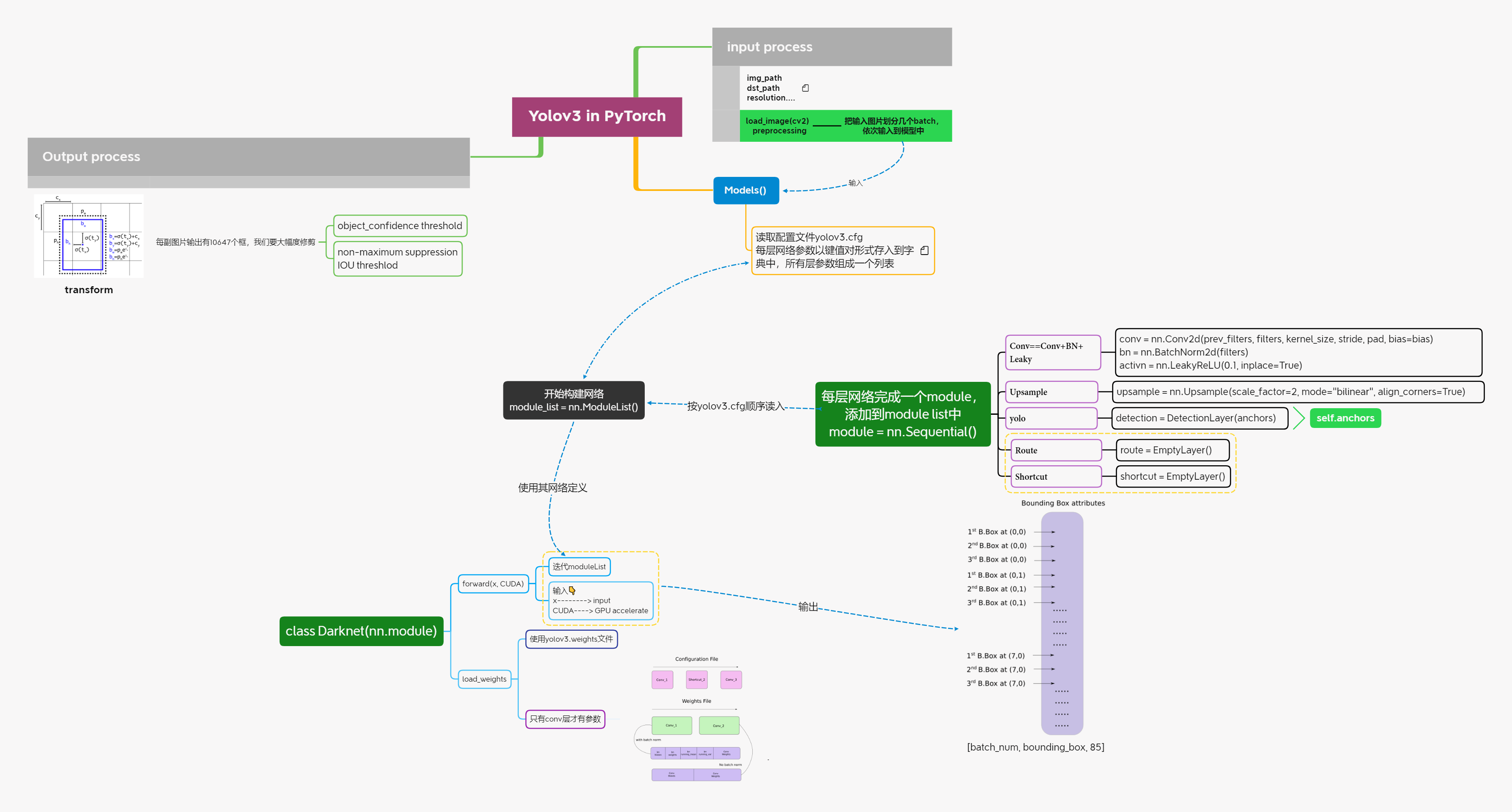
Implementation in PyTorch
Reference
本博客所有文章除特别声明外,均采用 CC BY-SA 3.0协议 。转载请注明出处!