Unprivileged Spec(1)--RV32I
本文最后更新于:Wednesday, September 30th 2020, 8:18 pm
1 Preface
- RV32I是为了足够成为编译器目标并能支持现代操作系统环境而设计的一个基本整数指令集。它也为了减少硬件实现的最小需求而设计。RV32I包含40个独立的指令,尽管一些简单的实现可能用单一的系统硬件指令(a single SYSTEM hardware instruction)代替ECALL/EBREAK指令,它总是捕获异常(always traps)并且可能将FENCE指令实现为NOP,以减少指令数到38个。RV32I能够模拟几乎任何的ISA扩展(除了A扩展,它需要额外硬件支持原子操作(atomicity)
- 在实践中,包含机器模式特权架构的硬件实现将需要9个CSR指令。
- 基本整数指令集的子集也许对于教学目的很有用(pedagogical purposes), 但是基础已经被定义,对实现其子集的真正的硬件除了忽略非对齐内存访问并把所有的SYSTEM instruction视为单一的异常(single trap),我们不应该有什么其它的动机。
关于RV32I的大多注释也适用于RV64I base。
2 Programmer’s Model
对于RV32I非特权状态一共有32个寄存器(都是32位宽,i.e. ,XLEN=32):
x0~x31;x0被硬编码到0。另外31个寄存器保存的值可以被解释为:Ⅰ、布尔值的集合,Ⅱ、补码的有符号二进制整数,Ⅲ、无符号二进制整数有一个额外的非特权寄存器,
pc(program counter):保存当前指令的地址
- 在Base Integer ISA中,没有指定的栈指针或者子例程返回地址链接寄存器(link register);指令编码允许任何寄存器被用于这个目的;但是,标准软件调用惯例(calling convention)使用寄存器
x1保存调用的返回地址,x5作为备用链接寄存器。标准调用例程使用x2作为栈指针(stack pointer) - 硬件可以使用
x1或x2来加速函数调用和返回(因为可以尽早解码);详情见JAL和JALR指令 - 可选的压缩16-bit指令格式基于这样的假设设计的:
x1:返回地址寄存器;x2:栈指针。使用其他约定的软件将正常运行,但可能有较大的代码大小。
notes:
- 可用架构寄存器(available architectural registers)的数量能够对
代码大小,性能,能耗产生重大影响。尽管16个寄存器对于运行编译代码的整数ISA来说是足够的,但是在长度为16位使用3-address格式的指令中编码拥有16个寄存器完整的ISA是不可能的。(⭐PS:16个寄存器,address至少4位,三地址就12位,那么只剩下4位区分不同的指令了,即最多16条不同的指令)。 - 尽管2-address是可能的。但它增加指令条数并且降低效率。我们想要避免立即数指令的大小来简化硬件实现,一旦32-bit的指令大小被采用,支持32个整数寄存器就很显而易见了。一个更大数量的整数寄存器也有助于提高高性能代码的性能,可广泛使用
循环展开(loop unrolling)、软件流水线(software pipelining)和缓存平铺(cache tiling)。❓ - 基于上面这些原因,我们为基础ISA选择了一个常规大小(conventional size)——32个整数寄存器。动态寄存器使用趋向于被一些经常访问的寄存器主宰,并且
regfile(寄存器堆)的实现可被优化以减少频繁访问寄存器的访问能量(access energy)。 - 可选的16位压缩指令格式绝大部分只使用8个寄存器,因此能提供稠密的指令编码(dense instruction encoding),但是如果想要的话,额外的指令集扩展能支持更大的寄存器空间(要么扁平的要么分层次的)。
3 Base Instruction Formats
有4种核心的指令格式:R/I/S/U。指令长度都是32位,并且必须在内存中以4字节为边界对齐。指令地址非对齐的异常,常常是由于分支的发生(taken branch)或者非条件跳转的目标地址不是4字节对齐。
对于解码一个保留指令的行为是没有规定的(unspecified)
RISC-V ISA保持源寄存器(
rs1和rs2)和目标寄存器(rd)的位置在所有指令格式中相同以简化解码。除了使用在CSR指令中的5bit的立即数,立即数总是sign-extended,通常是打包到指令中最左边的可用位,这样分配以减少硬件的复杂程度。特别是,对于所有立即数的符号位总是在最高位(也就是Ins[31])来加速符号扩展电路。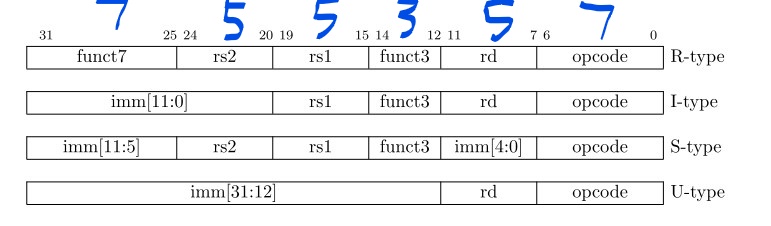
imm[x]指的是当前位在扩展成32位立即数中的位置 - 实际应用中,大部分立即数要么很小,要么需要所有的位数(XLEN bits)。我们选择非对称立即数分割:常规指令中立即数占12bits;特殊的 load-upper-immediate 指令中立即数占20bits。这样做是为了给常规指令更多的opcode空间。
4 Immediate Encoding
指令格式还有两个变种(variants):B/J,它们基于立即数的处理衍生出来。

- S和B仅有的区别:在B格式中12bit立即数域乘以2用于编码分支偏移。而不是像传统做法那样,将指令编码中的所有立即数位用硬件左移一位,中间的位数(imm[10:1])和符号位保留在固定位置,而S格式中的最低位(inst[7])在B格式中编码一个高阶位。
- U和J的仅有区别:U要向左移12位;而J只用移动1位。在U和J指令立即数中指令的位置尽量跟其他格式的指令或者它们互相重叠。

5 Computational
大多数的
整数算术指令(Integer computational instruction)对保存在整数寄存器中的XLEN位的值进行操作。整数计算指令要么被编码为使用I格式的寄存器-立即数操作;要么使用R格式的寄存器-寄存器操作。对于这两种类型指令的目的寄存器都是rd。没有整型计算指令会导致算术异常
基本指令集不包括对整数算术运算上做
溢出检查(overflow checks)支持的特殊指令集。因为许多溢出检查能够更便宜地(cheaply)使用RISC-V分支来实现对
无符号加法的溢出检查仅仅需要在加法指令后加上一条额外的分支指令1
2add t0,t1,t2
blut t0, t1, overflow对于有符号加法:如果一个操作数的符号已知,溢出检查仅需要加法之后的一个分支(覆盖了带有立即数操作数的常见加法情形)
1
2addi t0, t1, +imm
blt t0, t1, overflow对于常规的
有符号加法,加法之后需要三条额外的指令。利用当且仅当另一个操作数为负时,该和应小于其中一个操作数的观察。1
2
3
4add t0, t1, t2
slti t3, t2, 0
slt t4, t0, t1
bne t3, t4, overflow- 在RV64I中,32位有符号的加法溢出可以通过比较ADD和ADDW操作的结果来进一步优化。(ADDW肯定不会溢出)
Register-Immediate

ADDI:将12位立即数符号扩展后与rs1中的值相加,算术溢出忽略,结果的低32位存到rd寄存器中。1
2
3/* 两条指令等效 */
ADDI rd, rs1, 0
MV rd , rs1(汇编伪指令:将rs1中的值复制给rd)SLTI(set less than immediate): 当寄存器rs1中的值小于立即数(俩者都视为有符号数),将寄存器rd置为1;否则置0。SLTIU: 功能一样,但是把比较的对象视为无符号数。1
2
3/* 两条指令等效 */
SLTIU rd, rs1, 1(当rs1等于0,rd为1,否则为0)
SEQZ rd, rsANDI, ORI, XORI: 三个逻辑运算符,分别对rs1和立即数执行按位(bitwise)的与,或,异或运算。1
2
3/* 两条指令等效 */
XORI rd, rs1, -1(-1的补码为全1)
NOT rd, rs(将rs各位取反赋值给rd)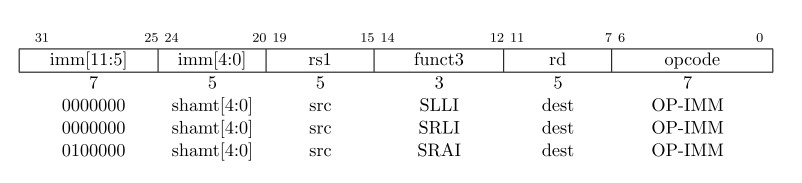
移位被编码一种特殊的I类型指令格式。
- 被移位的操作数为
rs1;移位的位数被编码在立即数域的低五位上。- 👉移类型被编码在第30位上;
SLLI(shift left logical):0被移动到低位SRLI: 0被移动到高位SRAI: (shift right arithmetic): 原符号位复制到空出的高位

LUI(load upper immediate): 用于构建32位常数并使用U格式指令。把U-immediate的值放在目的寄存器的高20位,其它低位用0填充。AUIPC(add upper immediate to pc):用于构建与pc相关的地址,并使用U格式指令。形成32位的偏移(高20位来自立即数,低12位用0填充),把这个偏移加到AUIPC指令的地址上,然后把结果放到rd中。(rd = pc-4+im)- AUIPC指令支持
双指令序列(two-instruction sequences)访问相对PC的任意偏移(for both control-flow transfers and data accesses) - 一个AUIPC和JALR中12位偏移的组合能够转换控制给任意32位的PC相对地址(PC-relative address),而一个ALIPC加上一个常规load和store指令中的12位立即数偏移能供访问任意32位PC相对地址的数据地址(PC-relative data address)
- 当前PC值可以通过设置立即数为0获得,尽管JAL+4指令也能获得本地PC(JAL下一指令),它可能在简单微架构中造成流水线崩溃,或者在更复杂的微架构中污染BTB(❓)
- AUIPC指令支持
Register-Register
RV32I定义了几个R型算术运算。所有的运算都读取
rs1,rs2寄存器的值作为源操作数,把结果写回rd寄存器。funct7和funct3域选择合适的运算。
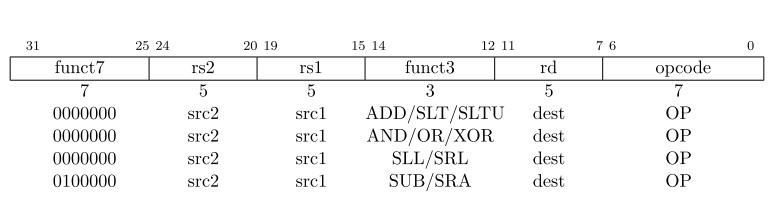
NOP Instruction

- NOP指令:不会改变任何架构上可见的状态。出来推进PC,增加任何适用的性能计数器。NOP被编码为`ADDI x0, x0, 0
- NOPs可以被用来对齐代码段与重要的微架构地址边界。或者为内联代码修改(inline code modification)流出空间。尽管有许多可能的方法去编码NOP,我们使用了规范的NOP编码来允许微架构优化以及更易读的反汇编输出。其它的NOP编码可以用作指示指令(HINT instruction)
- 选择ADDI作为NOP编码是因为它在跨一系列系统执行时最可能占用最少的资源;除此之外,该指令仅读取一个寄存器。并且,一个ADDI功能单元在超标量设计中更容易可用,因为adds是最常见的运算
- 地址生成单元可以使用相同的硬件够执行ADDI,该硬件被用于base+offset地址计算,而register-register ADD,逻辑运算或移位运算操作需要额外的硬件。
6 Control Transfer
RV32I提供两种控制转义指令:
无条件跳转,条件分支RV32I控制转义指令没有架构上可见的
延迟槽(delay slot)
Unconditional Jumps

JAL(jump and link)指令使用J-type格式,J-immediate以两字节的倍数编码一个有符号偏移。(in multiple of 2 bytes;则该偏移要乘以2)。偏移符号扩展,然后加上当前指令的地址形成跳转目标地址(jump target address)。Jumps因此能够访问±1 MiB范围。JAL存储下一条指令的地址(pc+4)到rd;
标准软件调用约定使用x1作为返回地址寄存器,x5作为备用链接寄存器。

JALR(jump and link register):间接跳转指令:使用I-type,目标地址通过把符号扩展的12比特立即数加到rs1上,然后置结果的最低位为0获得;下一条指令的地址(pc+4)写到寄存器rd。如果结果不需要,可以把x0当作目的寄存器。
如果目标地址没有对齐四字节边界,jar和jarl指令将产生指令地址非对齐异常。
返回地址预测栈(prediction stack)是高性能取值单元的一个常见特点,要求准确检测用于过程调用和返回的指令是有效的。
- 对于RISC-V,关于指令使用的线索通过寄存器号的使用被简单的编码。
- JAL指令应该把返回地址压进返回地址栈(RAS)中,当且仅当
rd = x1/x5; - JALR指令应该push/pop a RAS

Conditional Branches
所有分支指令使用
B-type格式。12比特的立即数用2字节的倍数编码有符号偏移
立即数符号扩展后与当前指令地址相加,可以访问的地址范围:
±4 KiB
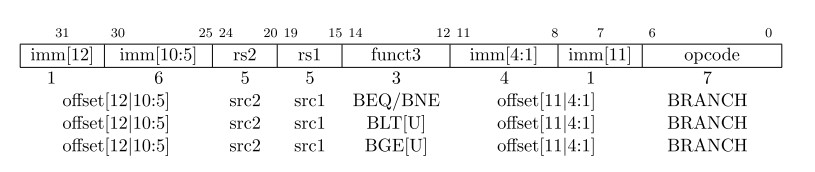
BEQ:branch equal; BNE: branch not equal; BLT: branch less than; BGE: branch greater than;
- 应该对软件进行优化,使顺序代码路径成为最常见的路径,并将较不经常使用的分支代码路径置于行外。软件还应该假设,至少在第一次遇到分支时,预测向后跳转的分支发生,向前跳转的分支不发生。动态预测器应该快速学习任何可预测的分支行为。
- 不像一些其它的架构,RISC-V中对于
非条件分支应该总是使用jump(JAL with rd=x0)指令而不是条件总是满足的有条件分支指令 - RISC-V跳转也是与pc相关的,并且比分支支持更大的偏置范围,而且不会污染条件分支预测表。
7 Load and Store(😳)
RV32I是一个装载和存储架构:只有
load和store指令能够访问内存,算术指令只能操作CPU寄存器。
- RV32I提供了32-bit的地址空间,用字节编码。
EEI定义了地址空间的那部分可以被哪些指令合法访问。(e.g.,一些地址可能只能被读,或仅支持按字访问)- 目的寄存器为
x0的装载指令将抛出异常,即使装载的值被丢弃也会造成其它的副作用。
In RISC-V,endianness is byte-address invariant
如果一个字节以某种顺序(at some endianness)存储到内存某个地址处,那么以字节大小从那个地址以任意的顺序(in any endianness)装载的结果是存储的值。
小端(little-endian): 多字节存储时把寄存器最低为字节写到内存字节地址的最低为,随后寄存器的其它字节以权重升序写入。(权重越大的字节占据的内存地址越大)
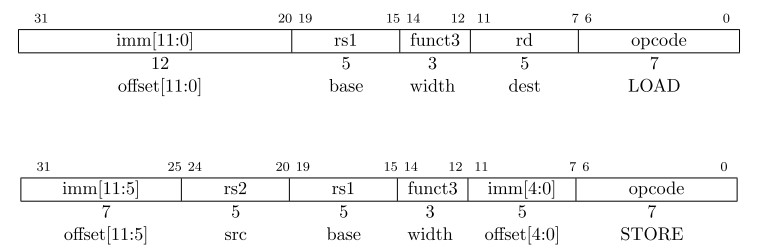
装载和存储指令用于在寄存器和内存中转换数据。
Loads:
I-typeStores:
S-type有效地址:立即数符号扩展加上基址寄存器
rs1目的地址:Ⅰ、for load:从内存取值到
rd;Ⅱ、for store:复制rs2的值到内存
8 Memory Ordering

FENCE:用于排序被其它RISC-V线程,外部设备或者协处理器可见的设备I/O和存储器访问。任何设备输入(I),设备输出(O),存储器读取(R),存储器写(W)的组合能够被排序成任何相同的组合。
- 通俗地说,没有其它线程或者外部设备能够在
fence之前的指令集进行任何操作之前,观测到在fence后者的指令集合所做的任何操作。就像一个屏障一样,前面的操作只有先完成,后面的指令结果才能被其它处理器观察到。 - memory-mapped I/O设备很典型地被没有cache的loads和store访问,它们使用I和O而不是R和W。
- 指令集扩展也可以描述新的I/O指令,使用fence指令中I和O位进行排序

- fence mode域在ins[31:28];当fm=0000时排序所有的内存操作。
- 可选的
FENCE.TSO指令其fm=1000;predecessor=RW,并且successor=RW。TSO命令它的前面集合中的所有加载操作先于它的后继集合中的所有内存操作;它的前面集合中的所有存储操作(store operation)都要先于它的后继集合中的所有存储操作
9 Call and Breakpoints
SYSTEM instruction:被用于访问需要特权访问的系统功能,使用
I-type。分为两大类:
- 自动读-修改-写(read-modify-write)
控制状态寄存器(CSRs)。- 潜在的特权指令(potentially privileged instructions)
系统指令被定义成运行稍简单的实现总是捕获异常给单一的
软件异常处理器(software trap handle);更加复杂的实现可能需要执行更多条系统指令

这两个指令会向配套执行环境(supporting execution environment)引起一个精确的请求异常(requested trap)。
ECALL
ECALL:向运行环境提出服务请求(service request)EEl将定义服务请求的参数如何传递,但通常这些都是在整数寄存器中指定的位置
EBREAK
EBREAK:返回控制权给调试器环境(debugging environment)
10 Hint
RV32I为
HINT指令保留了大的编码空间,通常是用来和微架构沟通性能提示。HINTs被编码为整数计算指令,其中rd=x0。因此,像nop指令一样,HINTs不会改变架构可见的状态,除了增加pc和任何适用的性能计数器。
本博客所有文章除特别声明外,均采用 CC BY-SA 3.0协议 。转载请注明出处!