数据通路(4)--Multiple Issue
本文最后更新于:Monday, September 28th 2020, 11:50 am
Preface
指令集并行(instruction-level parallelism)有两种方式Ⅰ、Pipeline——详见数据通路(3);流水线越深,并行度越高。
Ⅱ、
多发射(multiple issue): 本节所要讲述的重点。通过复制计算机内部部件的数量,使得每个流水级可以启动多条指令
- 多发射可以使指令执行速度超过时钟的速度,即CPI小于1。
- 实现多发射有两种办法:1、
static multiple issue;2、dynamic multiple issue。
多发射流水线必须处理以下两个问题:
- 打包指令到
发射槽(issue slots):在大多数静态多发射实现上:在一个时钟周期发射多少条指令,哪些指令被发射这个过程至少很大一部分由编译器来完成。而在动态发射处理器中,这个问题一般由处理器在运行时来处理。(尽管编译器已经优化了指令顺序来尽可能多发射) - 处理数据和控制冒险:在静态发射处理器中,编译器解决大部分或者所有的可能冒险。与此相反的,动态发射处理器用硬件技术在运行时至少消除某些类别的冒险。
尽管,我们把它们描述成不同的方法,但事实上,一个方法经常借助另外一个方法的技术。
Speculation(推测)
speculation: An approach whereby the compiler or processor guesses the outcome of an instruction to remove it as a dependence in executing other instructions
提前给出结果(猜测)来避免后面的指令对正在运行指令的依赖
以下是几种猜测的情形:
- 我们猜测分支的结果,那样分支后面的指令可以提早执行。
- 我们猜测存字和取字指令访问的不是同一个地址,那样我们在执行存字指令前去执行取字指令。
但是,猜测可能出现错误❌。所以:任何推测技术都必须包含一种机制:1、检查推测是否正确;2、回滚由于推测提前执行的指令的影响。
推测错误时恢复机制:
- for compile: 插入额外的指令检查推测的正确性✔并提供一个fix-up例程供推测错误时使用。
- for processor: 用buffer缓存推测结果直到推测的结果得到确认。如果推测正确,把缓存的能容写到相应的寄存器中,指令完成。如果推测不正确,硬件冲刷掉buffer,重新执行正确的指令序列。
推测可能引入另外的问题:对某些指令的推测会导致原本不存在的异常发生。比如,推测执行一条装载指令,在推测错误的情况下,该指令所使用的地址是非法的。
Static multiple-issue
Static multiple-issue processers all use the compiler to assist with packaging instructions and handling hazards.
issue packet(发射包):在一个时钟周期内可以发射的指令集合,可以用一条完成多种操作的长指令来类比
Very Long Instruction Word(超长指令字):一种指令集架构,能够发射多条操作,这些操作在单个指令中被定义为独立的,并且一般都有独立的操作码域。
静态多发射处理器有两种:
- 编译器避免所有冒险;
- 硬件检测数据冒险,并在两个发射包间产生阻塞,而编译器只负责避免一个指令包间的依赖。
为了并行发射ALU和数据传输操作,需要有额外的硬件:
- 寄存器堆要有额外的端口供连个操作读取操作数;
- 要有额外的ALU来同时执行EX阶段。
多发射带来的问题:由于额外的指令重叠,冒险的可能性加倍。
- 装载指令有一个时钟周期的
使用延迟(use latency);这意味着下一个发射包中所有指令都不能使用装载的结果。 - 原本没有使用延迟的ALU指令,其结果不能被在同一个发射包的其他指令使用。
- 装载指令有一个时钟周期的
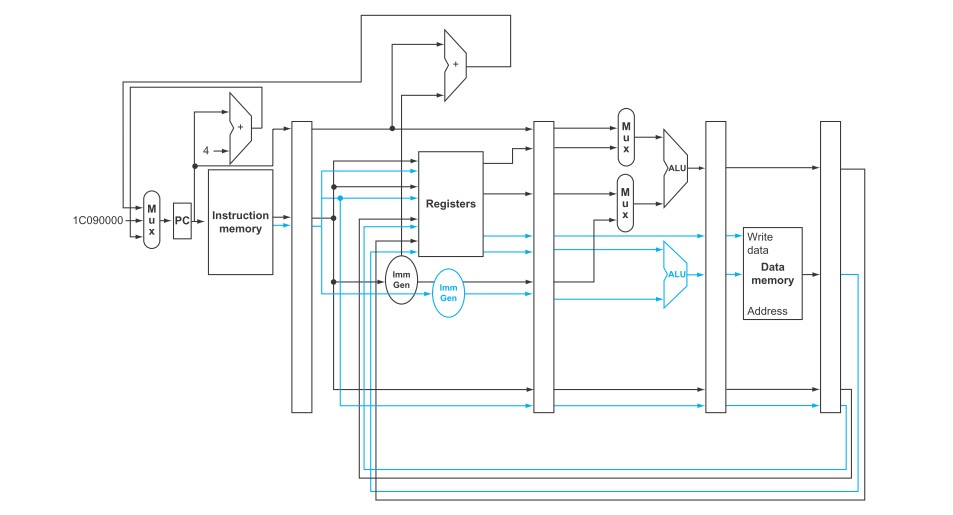
循环展开(loop unrolling):一种从访问数组的循环程序中获得更多性能的技术。其中循环体会被复制多份并且在不同循环体中的指令会调度在一起。
1 | |
不进行循环展开的静态多发射调度:
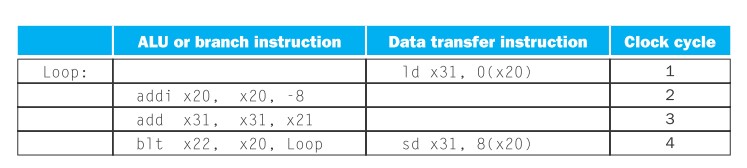
循环展开结果:
- 在循环展开过程中,编译器引入了几个临时编译器(x28、x29、x30)。这个过程叫做
寄存器重命名: 目的是消除一些虚假依赖。 - 如果我们只使用x31寄存器:我们将在sd x31,8(x20)后面重复ld x31,0(x20), add x31, x31, x21。但是这些序列尽管都使用x31,它们实际上是不相关的。
antidependenceorname dependence(反相关或名字相关):一组指令集和下一组指令集之间no data value flow,仅仅是因为重用寄存器名引起的相关。
Dynamic multiple-issue
Dynamic multiple-issue processors are also known as superscalar processors, or simply superscalars
Basic concept
最简单的超标量处理器:指令按顺序发射,处理器决定每个周期发射0条,1条或多条指令。
显然为了获得好的性能,处理器仍然需要编译器帮忙编排指令顺序来减少依赖。
简单超标量处理器与VLIW处理器(静态发射)的区别:
- for superscalar::1、不管是否经过编译器编排指令顺序,都由硬件来保证执行的正确性✔。2、编译过的代码将始终正确的运行,无论发射速率还是流水线架构。
- for VLIW:不像👆那样,当移植到不同的处理器模型往往需要重新编译。在其他的静态发射处理器中,代码能够在不同的处理器实现上正确运行,但是效率很差也需要重新编译。
许多超标量处理器扩展了基本的动态发射策略,将dynamic pipeline scheduling(动态流水线调度)包含进来。
1 | |
说明:即使sub指令准备好执行,它也必须等待ld和add指令先结束才行。如果内存很慢,sub指令可能会等待多个周期(比如cache没有命中)
dynamic pipeline scheduling
Dynamic pipeline scheduling chooses which instructions to execute next, possibly reordering them to avoid stalls.
动态调度可以运行时动态调整指令顺序
流水线被分为三个主要部分:
- an instruction fetch and issue unit(取指发射单元)
- multiple functional units(多种功能单元)
- commit unit(提交单元)
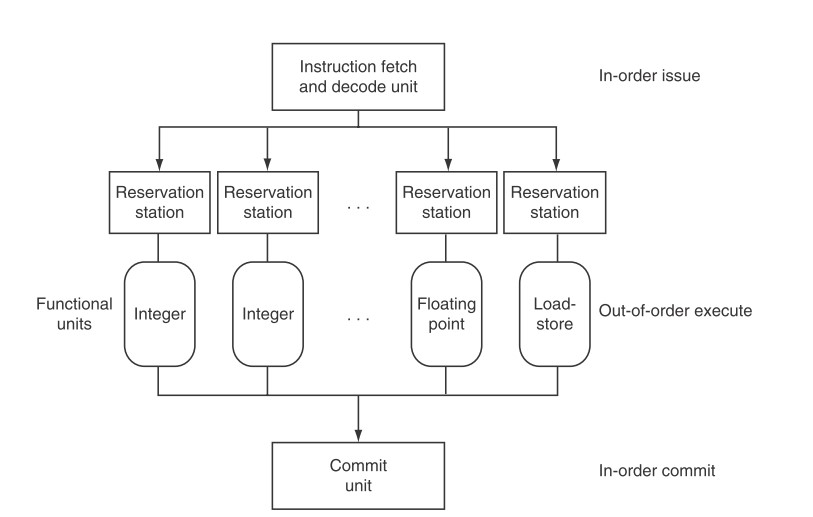
- 每个功能单元有个buffer, 称为
保留站(reservation station),其中保存着操作数和操作(opcode ❓)。 - 功能单元运算完成的结果传送给1、commit unit;2、旁路给所需的保留站。
- 提交单元也有buffer,称为
reorder buffer(重排序缓冲区):缓存结果直到确定是安全时才写入register file或者memory。
保留站缓存操作数➕提交单元缓存结果==》寄存器重命名
- 发射指令时,它被复制到对应功能单元的保留站上,如果它的操作数在寄存器堆或者提交单元缓冲区中有,那么操作数立马复制到保留站。如果指令已经发射,那么对应操作数的副本不再需要,可以重写覆盖。
- 如果一个操作数不在register file or reorder buffer,他必须等待某个功能单元的结果。硬件帮助追踪所需的功能单元,当单元计算出结果直接复制到保留站而旁路掉寄存器堆。
out-of-order execution(乱序执行):处理器在不违背原有数据流顺序的前提下以某种顺序执行各条指令,但是执行指令的顺序可以与取指不同。
in-order commit(顺序提交):流水线执行的结果以取指顺序写回程序员可见的寄存器的一种提交方式。(当异常发生时,处理器可以找到最后执行的那条指令,而只有这条导致异常的指令之前的指令才能对寄存器状态进行改变。
推测和动态调度经常结合在一起:
- 通过对分支的预测,动态调度可以在推测方向上进行取指和执行。由于指令是顺序提交,我们可以在分支指令及所有推测执行的指令提交前知道推测是否准确。
- 通过对装载指令目的地址的预测,对存取指令进行重排序和利用提交单元避免错误的推测。
本博客所有文章除特别声明外,均采用 CC BY-SA 3.0协议 。转载请注明出处!